







 本文介绍了学习Dijkstra算法的过程,揭示了其与动态规划的内在联系。通过手动跟随算法步骤,发现最短路径P由各段最短路组成,这是动态规划的基础。Dijkstra算法使用归纳和反证法证明正确性,通过维护已找到最短路径的点集合S和待计算的点集合U,不断选择距离源点最近的点进行更新,直至所有点的最短路径计算完成。文章讨论了算法中选择点2和点6作为最短路径的理由,并通过反证法进行了说明。
本文介绍了学习Dijkstra算法的过程,揭示了其与动态规划的内在联系。通过手动跟随算法步骤,发现最短路径P由各段最短路组成,这是动态规划的基础。Dijkstra算法使用归纳和反证法证明正确性,通过维护已找到最短路径的点集合S和待计算的点集合U,不断选择距离源点最近的点进行更新,直至所有点的最短路径计算完成。文章讨论了算法中选择点2和点6作为最短路径的理由,并通过反证法进行了说明。
网上有看到 Dijkstra算法和 动态规划啦,贪心啦什么的有关。
一开始一头雾水的,怎么就和动态规划有关? 哪来的最优子问题结构?
后来经过手动跟一遍 Dijkstra过程,突然醒悟到:
如果 P = A1 A2 ... An 是最A1 到An的最短路, 那么 P 包含了其中任意两点之间的最短路。
否则如果P的两点 Ai Aj 之间存在更短的路, 那么总可以替换掉,从而令P更短。
因此如果P是最短路,那么必定是由各段的最短路组成的。 这就是动态规划的基础了
正确性的证明用归纳法+ 反证法
算法过程:
维护两个点集合 S,U. S并U就是整个图的点。S 是已经找到最短路的点,U是还待计算的。
每次从U中选择一个点P进入S。
那么P怎么选呢? 当前的U中,选择距离源点最近的。
直到U空集,全部点到源点的最短路都计算出来了。
| S | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 1 | 0 | 4 | 6 | ∞ | 4 | ∞ | ∞ |
| 1,2 | 0 | 4 | 6 | ∞ | 4 | 9 | ∞ |
| 1,2,5 | 0 | 4 | 6 | 6 | 4 | 9 | ∞ |
| 1,2,5,3 | 0 | 4 | 6 | 6 | 4 | 9 | ∞ |
| 1,2,5,3,4 | 0 | 4 | 6 | 6 | 4 | 9 | ∞ |
| 1,2,5,3,4,6 | 0 | 4 | 6 | 6 | 4 | 9 | 12 |
| 1,2,5,3,4,6,7 | 0 | 4 | 6 | 6 | 4 | 9 |
12
|
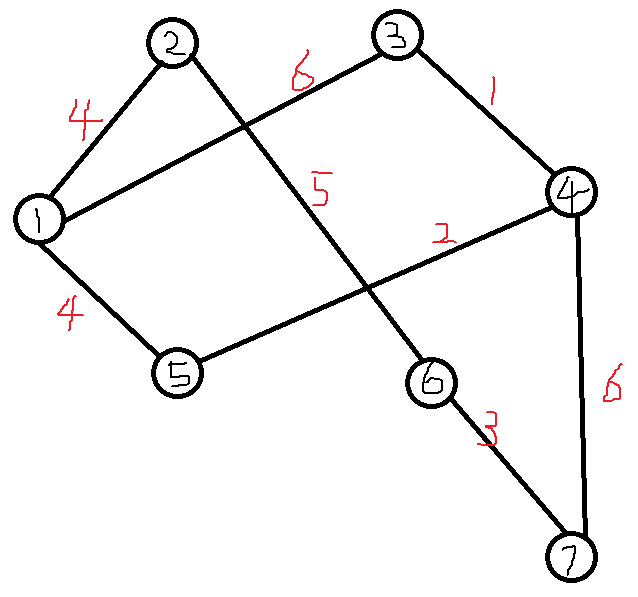
求出从点1到其他点的最短路。
1、一开始S中只包含点 1, 表格第一行其实是初始化的值,1 的邻接点的权重,非邻接点权重为无穷。
2、从U中选则距离最小的, 也就是点2. 加入到S中。 并且以2为中继点更新U中各点的最短距离。以点6为例,原本到6的距离是无穷大;而经过2到达6的距离是9,比无穷小,因此更新U中点6 的距离。
3、通过点2更新完U的点之后,再从U中取出新的距离最小的点,点5. 再次更新。以点4为例,原本点4不可达,经过5到达4的话,只需要6距离,因此更新。
一直重复直至U空了 / S包含全部点。
算法结束后,最后一行就是各个点的最短路
问题来了:
1、 第二行中,为什么能确定点2就是最短路呢?
反证法: 如果存在点K, 1-K-2会更加短,那么1-K 必定比1-2更小,但是我们之所以选到点2,就是因为他是1可达的各点中最小的了,所以不存在这样的K。
2、第5行,为什么能确定点6就是最短的呢?
因为从1到点6 的距离是通过之前的S(1,2,5,3,4)中的点得到的, 如果此时6的距离还不是最小的,那么只可能是1经过U(7)中的某点到达6.
也就是说,经过1 出发到7会更短,这和6 的选择是矛盾的。
其实这就是数学归纳的过程, 奠基的一步是问题1, 之后每步的选择都保证选出的点是已经算出最短路径的了。
const int infinity = 0x6fffffff; //无穷应选择什么数需要看情况,既要防止溢出,又要保证足够大
//算法结束后, distance保存各点最短路
void Dijkstra(int source, int n, int distance[], int *adjacency[]) //adjacency非邻接点权重无穷大
{
bool found[n]; //found[i] 为true 表示点 i在S中
int i,j;
for (i=0; i<n; i++)
{
found[i] = false;
distance[i] = adjacency[source][i];
}
found[source] = true;
distance[source] = 0;
//initialization finish
for (i=0; i<n; i++)
{
int min = infinity;
for (j=0; i<n; j++) //找到 U 集合中最小的点加入到 S中
{
if ( found[j] ) continue;
if (distance[j] < min)
{
min = distance[j];
}
}
found[j] = true;
for (i = 0; i<n; i++)
{
if ( found[i] ) continue; //S集合中的已经是最短路,无需更新
if ( min + adjacency[j][i] < distance[i]) // 经过新的最短点j 再到达 i,比之前的走法更短就需要更新
{
distance[i] = min + adjacency[j][i];
}
}
}
}















 3496
3496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









